
从揭晓新AI处理器致意女天体裁家,到发布首款开源机器东谈主模子开yun体育网,再到盛赞DeepSeek并强调不会冲击自家芯片需求,终末又发布一款新推理模子堪称不错秒杀DeepSeek;这组成了今天黄仁勋在GTC大会主题演讲的几个精彩时刻。
如故那身玄色皮衣,黄仁勋走上GTC舞台,告示我方依然不会使用提词器,以致札记王人莫得准备。情感随心是他的演讲象征立场,拿着幻灯片遥控器就不错一谈说下去。

今天在加利福尼亚州圣何塞举办的GTC 2025大会上,英伟达CEO黄仁勋向大家展示了他们在东谈主工智能(AI)领域的最新本领干豫。从告示下一代GPU架构到将AI带入商用,告示快餐巨头Taco Bell的合作,英伟达不仅安适了其在AI估计领域的调换地位,还将其本领触角蔓延至零卖管业绩。
这是英伟达在疫情之后第二次在圣何塞举办GTC大会。本次大会眩惑了约2.5万名与会者,包括微软、谷歌、Waymo和福出奇行业巨头,共同探讨AI硬件的异日应用。
早上八点SAP畅通场外就排起了队,只为了尽早入场现场凝听黄仁勋的主题演讲,因为体育馆场内座位有限,排在后头的只可在外面看大屏幕。黄仁勋开打趣称,我方需要更大的会场。
为什么GTC大会如斯眩惑关注?动作AI期间的引擎提供商,英伟达在短短两年就成为了半导体巨无霸,以致一度市值畸形苹果,成为了大家市值最高企业。不夸张地说,通盘科技行业王人在密切关注英伟达的每一次发布会,关注着新一代处理器,因为这顺利筹谋到异日几年的AI算力。
那么今天的GTC 2025,黄仁勋告示了哪些重磅产物与音问?
新处理器致意女天体裁家
如外界预期,黄仁勋在主题演讲中发布了全新AI处理器“Vera Rubin”,以好意思国女天体裁家维拉·鲁宾(1928-2016)定名。这款芯片整合了英伟达首款定制CPU “Vera”和全新想象的GPU,象征着英伟达在处理器想象上的要紧干豫。这款处理器展望于2026年下半年出货。
Vera CPU基于英伟达自研的Olympus中枢架构,此前英伟达多依赖Arm的现成想象(如Cortex系列)。定制化想象让Vera在性能上比Grace Blackwell芯片中的CPU快约两倍,具体阐扬为更高的每时钟周期领导数(IPC)和更低的功耗。

英伟达线路,这款全新处理器将遴荐台积电的3nm工艺制造,晶体管密度较5nm工艺晋升约2.5倍,达到每平方毫米约1.5亿个晶体管。这种工艺向上权贵晋升了估计服从,尤其合乎AI推理任务的高并行需求。
Rubin GPU本领上由两个沉静芯片组成,通过英伟达的NV-HBI(High Bandwidth Interface)本领以超高带宽互联,职责时阐扬为单一逻辑单位。其中枢规格包括维持高达288GB的HBM3e内存(高带宽内存第三代增强版),带宽达每秒5TB,比Blackwell的HBM3内存(141GB,带宽4TB/s)晋升权贵。
在推理任务中,Rubin可兑现50 petaflops的性能(每秒5´10¹⁶次浮点运算),是现时Blackwell芯片(20 petaflops)的两倍多。这一晋升成绩于其新增的Tensor Core单位,专为矩阵运算优化,加快深度学习模子的推理和熟习。

Rubin的目的客户包括亚马逊和微软等云做事商和AI计议机构。其高内存容量和估计身手畸形合乎驱动大型讲话模子(如Llama 3或Grok),这些模子宽绰需要数百GB内存来存储权重和中间驱散。英伟达还展示了Rubin维持的新软件用具包Dynamo,可动态优化多GPU协同职责,进一步晋升性能。
除了Rubin之后,黄仁勋还告示英伟达有野心在2027年下半年推出”Rubin Ultra”,将四个GPU芯片集成于单一封装,性能高达100 petaflops。
Rubin Ultra遴荐名为NVLink 5.0的下一代互联本领,芯片间带宽展望达每秒10TB,比NVLink 4.0(600GB/s)晋升一个数目级。这种想象允许将多个Rubin Ultra组合成超等估计集群,如Vera Rubin NVL144机架(含144个GPU),为超大鸿沟AI熟习提供维持。
Rubin Ultra的每个GPU中枢展望包含畸形200亿个晶体管,遴荐2nm工艺制造,功耗限制在约800W以内(比拟Blackwell单芯片700W)。其内存维持升级至HBM4,提供高达576GB容量,带宽展望达每秒8TB/s。这种设置使其能处理复杂的生成式AI任务,果真时视频生成或多模态模子推理。
诚然Rubin两款处理器堪称怪兽级别,但商场需要比及光芒年身手部署。英伟达有野心本年下半年推出现时Blackwell系列的增强版产物——Blackwell Ultra。

Blackwell Ultra提供多种设置,包括:
- 单芯片版块(B300):20 petaflops性能,288GB HBM3e内存;
- 双芯片版块(GB300):搭配Arm CPU,功耗约1kW;
- 机架版块:含72个Blackwell芯片,适用于数据中心。
Blackwell Ultra的亮点是内存升级(从192GB增至288GB)和更高的token生成速率。英伟达称,其每秒可生成更多AI输出(如文本或图像),合乎时期敏锐的应用。云做事商可哄骗其提供高档AI做事,潜在收入可能是2023年Hopper芯片的50倍。
此外,黄仁勋还显露,英伟达有野心在2028年将推出以物理学家理查德·费曼(Richard Feynman)定名的Feynman GPU。Feynman将持续Vera CPU想象,但架构细节未公开。展望其将遴荐1.5nm工艺,性能可能干豫200 petaflops,目的是维持下一代AI代理模子,如具备推理身手的自主系统。

黄仁勋强调,英伟达已从两年一次的架构更新转向每年更新发布的节律,以应酬AI需求的“超加快”增长。自2022年底ChatGPT发布以来,英伟达销售额激增六倍,其GPU占据AI熟习商场畸形大略的商场份额。
上月底发布的第四季度财报自满,英伟达当季收入达到393亿好意思元,环比增长12%,同比增长78%。全年收入为1305亿好意思元,同比增长114%。其中数据中心收入为356亿好意思元,占总收入的91%,较上一季度增长16%,同比增长93%。这一增长不仅来自Hopper GPU的抓续销售,还包括Blackwell芯片的初步孝顺。
首款开源东谈主形机器东谈主模子
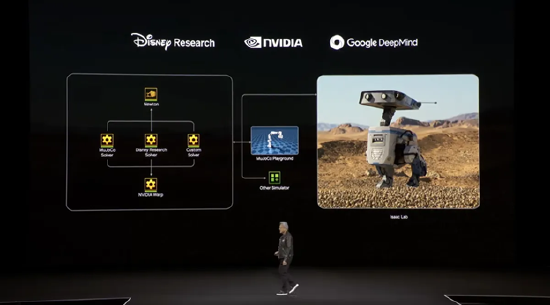
黄仁勋还在主题演讲中,负责发布了NVIDIA Isaac GR00T N1,告示“机器东谈主的期间依然到来”,这是大家首款开源的东谈主形机器东谈主基础模子。这是英伟达“Project GR00T”技俩的最新服从,基于其在2024年GTC大会上初度推出的机器东谈主计议技俩。
N1代表“第一代”,是英伟达专为加快东谈主形机器东谈主开采想象的通用AI模子。与传统机器东谈主依赖特定任务编程不同,GROOT N1是一个“通才模子”(generalist model),能够处理多种任务并妥当不同的东谈主形机器东谈主样式。
该模子使用确切数据和合成数据(synthetic data)夹杂熟习,其中合成数据由英伟达的Omniverse平台生成。这种方法大幅假造了本质天下数据积存的资本和时期。GROOT N1以开源神态发布,开采者可通过Hugging Face和GitHub下载其熟习数据和任务评估场景。这种怒放性旨在鼓吹大家机器东谈主社区的互助改革。

黄仁勋在主题演讲中现场演示展示了GROOT N1的商用实力:
1X NEO Gamma:1X公司的NEO Gamma东谈主形机器东谈主使用GROOT N1的后期熟习策略(post-trained policy),展示了自主整理家居的身手。1X CEO Bernt B
ørnich称:“GROOT N1在机器东谈主推理和妙技上的干豫,让咱们仅用小数数据就兑现了全面部署。”
迪士尼BDX机器东谈主:两台受《星球大战》启发的BDX机器东谈主(昵称“Green”和“Orange”)在台上跟班黄仁勋移动,并对他的领导(如“目下不是吃饭时期”)作念出点头回话,展现了当然讲话联贯和动作调解身手。
黄仁勋在演讲中指出,GROOT N1的发布不仅是本领干豫,亦然对异日机器东谈主产业的计谋布局。他预测,东谈主形机器东谈主商场在异日十年可能达到380亿好意思元,尤其在工业、制造和做事领域。他线路:“GROOT N1和新的数据生成框架将开启AI期间的新前沿。”
AI点餐带入连锁餐厅
在这次大会上,黄仁勋还告示了英伟达与大家餐饮巨头百胜餐饮(Yum! Brands)的计谋合作,百胜旗下的墨西哥风范餐厅Taco Bell将率先引入AI优化得来速做事(Drive Thru,不下车语音点餐)。
目下,数百家Taco Bell餐厅已使用英伟达提供的语音AI系统接管订单。百胜餐饮有野心从2025年第二季度起,将该本领推论至约500家餐厅,包括必胜客、肯德基和Habit Burger and Grill。
英伟达为Taco Bell定制了基于Transformer架构的语音识别模子,驱动于边际成立(如Nvidia Jetson平台)。该系统维持及时语音转文本(ASR)和当然讲话处理(NLP),延迟低至200毫秒。

百胜餐饮高管先容了英伟达本领奈何给我方做事带来晋升:AI将升级为视觉+语音系统,哄骗录像头和英伟达GPU分析列队车辆数目。举例,当检测到五辆车列队时,AI可提出快速出餐的选项(如Taco而非复杂的Burrito),裁汰平均恭候时期(目的从180秒降至120秒)。英伟达的推理加快本领(如TensorRT)将维持这些及时决策。
英伟达并不是起原尝试将AI带入快餐行业的巨头。早在2021年,IBM就和麦当劳合作,在100多家餐厅测试AI语音点餐,但使用体验还存在诸多问题,频繁会有听错点餐的情况,准确率唯有80%阁下,两边依然在2024年收尾了测试合作。
与百胜餐饮合作是英伟达将AI带入快餐行业做事的第一步,他们昭着也吸取了IBM的测试训导。英伟达零卖业务发展总监安德鲁·孙指出,AI需兼顾速率与质料,幸免给用户带来偏差,成为酬酢收罗笑柄。百胜餐饮高管强调,职工和顾主的信任至关要紧:“通用大模子不够好,咱们需要定制化责罚决策。”举例,Taco Bell的AI需联贯品牌文化,而非机械实施活动过程。
对DeepSeek拍案叫绝
值得一提的是,黄仁勋在主题演讲中,对来自中国的AI公司DeepSeek拍案叫绝,给以了极高的评价,屡次强调DeepSeek不会给英伟达带来冲击。黄仁勋在演讲中惊叹DeepSeek的R1模子为“非凡的改革”(excellent innovation)和“天下级的开源推理模子”(world-class open-source reasoning model)。
本年1月DeepSeek发布R1模子之后,以极低的熟习资本提供了失色以致优于OpenAI的性能,震荡了通盘好意思国AI行业,以致一度导致芯片行业股价大跌。因为如若DeepSeek得以普及,AI行业就不一定需要疏漏武备竞赛囤积英伟达的AI处理器了。

黄仁勋畸形反驳了商场早前的张皇,即DeepSeek的高效模子会假造对英伟达芯片的需求。黄仁勋提到,DeepSeek R1发布后(2025年1月),商场曾误以为AI硬件需求会减少,导致英伟达市值一度暴跌6000亿好意思元。他对此解说称,“商场以为’AI完成了’,咱们不再需要更多估计资源。这种想法十足空虚,恰巧违反。”
他强调,DeepSeek R1代表的“推理型AI”(reasoning AI)一样需要对很高的估计身手。他解说说,与传统不雅念以为AI仅需预熟习后即可顺利推理不同,推理型模子需要普遍后期熟习和及时算力维持。他线路:“推理是一个止境消耗估计资源的过程。像DeepSeek这么的模子可能需要比传统模子多100倍的估计身手,异日的推理模子需求还会更高。”
他指出,DeepSeek的胜利标明高效模子与宏大算力的麇集是异日趋势,而英伟达的芯片(如Blackwell Ultra)恰是为此定制的。他还幽默地称:“DeepSeek焚烧了大家关心,这对咱们是好音问。”英伟达已与包括Meta、谷歌和亚马逊在内的客户加大投资,确保其芯片闲隙日益增长的AI基础要道需求。
他指出,R1的发布不仅莫得缩小英伟达的商场面位,反而鼓吹了大家对AI的关心。“简直每个AI开采者王人在使用R1,这标明其影响力正在扩大AI的遴荐范围。”
黄仁勋因此显露,英伟达依然将DeepSeek R1动作新品基准测试的一部分。举例,他提到Blackwell Ultra芯片在想象时优化了推理任务,能更高效地驱动R1这类模子。他具体指出:“Blackwell Ultra的Tensor Core经过转换,维持高密度矩阵运算,每秒token生成率权贵晋升,相配合乎推理型AI。”
面临DeepSeek激励的竞争压力,黄仁勋淡化了对英伟达的威迫。他在演讲中说:“DeepSeek展示了模子不错更高效,但这并不虞味着硬件需求减少。违反,它让整个东谈主禁闭到,高效模子需要更强的估计维持。”

新推理模子秒杀DeepSeek
盛赞完DeepSeek,黄仁勋又告示推出了一款基于Llama的新推理模子——Nvidia Llama Nemotron Reasoning。他将这一模子描绘为“一个任何东谈主王人能驱动的令东谈主难以置信的新模子”,并强调其在企业AI应用中的后劲。这一发布象征着英伟达在AI模子开采领域的进一步膨胀,从硬件供应商向软件与模子生态的全面参与者转型。
黄仁勋畸形强调了Nvidia Llama Nemotron Reasoning在准确性和速率上的非凡阐扬,宣称其“大幅超越”(beats substantially)中国AI公司DeepSeek的R1模子。
Nvidia Llama Nemotron Reasoning是英伟达Nemotron模子家眷的新成员。Nemotron系列领先想象用于增强AI代理的身手,尽管“AI代理”这一观念在行业中仍未十足明确界说。宽绰,AI代理被联贯为能够自主实施任务、推理并与环境交互的智能系统,举例客服机器东谈主或自动化助手。黄仁勋在演讲中并未驻防解说“AI代理”的具体含义,但暗意Nemotron Reasoning将为企业提供更宏大的推理身手,维持复杂决策和任务处理。
该模子基于Meta开源的Llama架构,但经过英伟达的深度定制和优化。Llama动作一个高效、开源的大讲话模子基础,连年来被世俗用于学术和买卖领域,而英伟达通过其算力上风和软件生态(如TensorRT和Dynamo)对Llama进行了性能晋升,使其适配企业级应用。
Llama Nemotron家眷模子将与DeepSeek竞争,为高档代理提供企业就绪的AI推理模子。顾名想义,Llama Nemotron基于Meta的开源Llama模子。英伟达通过算法修剪了模子,以优化估计需求,同期保抓准确性。
英伟达还应用了复杂的后期熟习本领,使用合成数据进行熟习。熟习过程触及36万个H100推理小时和4.5万个小时的东谈主工标注,以增强推理身手。据英伟达称,整个这些熟习训诲了在数学、用具调用、领导撤职和对话任务等重要基准测试中具有非凡推理身手的模子。
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
包袱剪辑:郝欣煜 开yun体育网